实验室风采






具身智能实验室(SNNU-Embodied AI) 本团队是一支来自陕西师范大学,怀揣着对计算机视觉和人工智能的狂热喜爱,富有理想和追求的一流研发团队。在陕西师范大学人工智能与计算机学院裴炤教授的带领下,依托于现代教学技术教育部重点实验室,团队长期从事计算机视觉、具身智能等前沿基础理论和应用开发的研究, 承担了国家自然基金面上项目、国家自然基金青年项目、陕西省重点研发计划、陕西省自然科学基金等科学研究项目。在计算机视觉、图像处理、具身智能与人工智能研究领域,取得了一批有影响的研究成果。我们非常欢迎爱好计算机视觉与图像处理、人工智能和具身智能的同学前来加入我们的行列,攻读硕士或博士学位。
在校生

研究生,2023级

研究生,2023级

研究生,2023级

研究生,2024级

研究生,2024级

研究生,2024级

研究生,2025级

研究生,2025级

研究生,2025级

研究生,2025级

本科生,2022级

本科生,2022级

本科生,2024级

本科生,2024级

本科生,2024级
毕业生

博士后,2025年出站
海南大学 副教授

研究生,2025届

研究生,2025届

研究生,2025届

研究生,2024届

研究生,2024届

研究生,2024届

研究生,2023届
优秀毕业研究生
优秀研究生学位论文
就职于深圳思尔芯

本科生,2023届
悉尼大学
攻读硕士学位

本科生,2023届
陕西师范大学
攻读硕士学位

本科生,2023届
悉尼大学
攻读硕士学位

研究生,2022届
就职于北京
广联达科技股份
有限公司

研究生,2022届
就职于成都
亚控科技发展
有限公司

本科生,2022届
优秀毕业论文
就职于上海哔哩哔哩
科技有限公司

本科生,2022届
保送至陕西师范大学
攻读硕士学位

本科生,2022届
保送至陕西师范大学
攻读硕士学位

研究生,2021届
优秀毕业研究生
就职于安徽电信

研究生,2020届
优秀毕业研究生
北京交通大学
攻读博士学位

研究生,2020届
优秀毕业研究生
就职于西安浦发银行

本科生,2020届
优秀本科毕业生
保送至中山大学
攻读硕士学位

本科生,2020届
优秀毕业论文
就职于西安浦发银行

本科生,2020届
保送至华中科技大学
攻读硕士学位

研究生,2019届
优秀毕业研究生
就职于深圳康佳

本科生,2019届
四川大学
攻读硕士学位

本科生,2019届
优秀本科毕业生
优秀毕业论文
保送至中科院计算所
攻读硕士学位

本科生,2018届
保送至
北京航空航天大学
攻读硕士学位

本科生,2018届
保送至华中科技大学
攻读硕士学位

本科生,2018届
就职于北京链家

本科生,2017届
保送至西安交通大学
攻读硕士学位

本科生,2017届
保送至北京交通大学
攻读硕士学位

本科生,2016届
优秀本科毕业生
保送至天津大学
攻读硕士学位

本科生,2016届
就职于广州酷狗公司

本科生,2016届
就职于北京华为

本科生,2015届
优秀毕业论文
保送至西北工业大学
攻读硕士学位
项目
- [1] 国家自然科学基金面上项目 (2025.1-2028.12,主持)
- [2] 国家自然科学基金面上项目 (2020.1-2023.12,主持)
- [3] 国家自然科学基金青年项目 (2016.1-2018.12,主持)
- [4] 陕西省重点研发计划(2024.1-2025.12,主持)
- [5] 陕西省重点研发计划(2021.1-2022.12,主持)
- [6] 陕西省重点研发计划(2018.1-2019.12,主持)
- [7] 陕西省自然科学基金青年项目(2015.1-2016.12,主持)
- [8] 陕西省留学人员科技活动择优资助项目(2023.1-2024.12,主持)
- [9] 空天地海一体化大数据国家工程实验室开放课题(2020.1-2021.12,主持)
- [10] 中央高校基本科研业务费专项资金特别支持项目(2017.1-2019.12,主持)
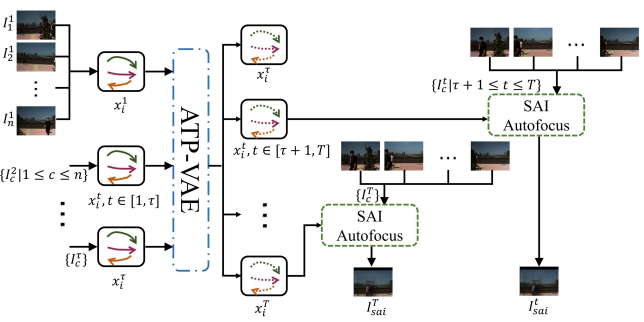
Occlusions and complex backgrounds are common factors that hinder many computer vision applications. In a street scene, the challenge of accurately predicting pedestrian trajectories comes from the complexity of human behavior and the diversity of the external environment. In this paper, we propose a joint prediction method based on autofocusing of SAI to predict pedestrian trajectories in dynamic scenes. The main contributions of this paper include: 1) The task of pedestrian trajectory prediction in dynamic scenarios is redefined as pedestrian trajectory prediction and SAI autofocusing from a practical but more challenging perspective. 2) The proposed method is based on an existing SAI-based method to extract information in heavily occluded views, which can obtain more accurate results but with less computational cost and without using other sensors such as LiDAR or depth cameras. 3) A new pedestrian trajectory prediction model, an attention-based trajectory prediction variational autoencoder (ATP-VAE), is proposed to extract complex human behavior and social interactions in dynamic scenes through a new Intention Attention Unit. The experimental results on multiple public datasets show that the proposed method achieves state-of-the-art results in the first-person perspective and in aerial view.
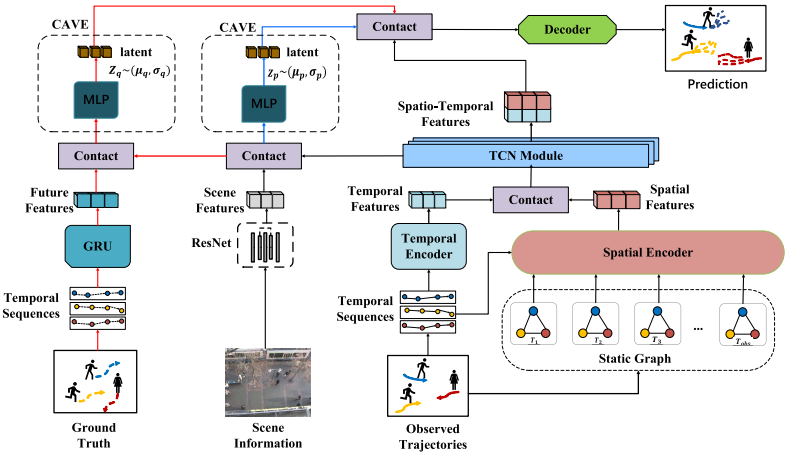
Pedestrian trajectory prediction in crowd scenes plays a significant role in intelligent transportation systems. The main challenges are manifested in learning motion patterns and addressing future uncertainty. Considering that the transformer network has a strong capability of capturing spatial and long-term temporal dynamics, we propose Long-Short Term Spatio-Temporal Aggregation (LSSTA) network for human trajectory prediction. First, a modern variant of graph neural networks, named spatial encoder, is presented to characterize spatial interactions between pedestrians. Second, LSSTA utilizes a transformer network to handle long-term temporal dependencies and aggregates the spatial and temporal features with a temporal convolution network (TCN). Thus, TCN is combined with the transformer to form a long-short term temporal dependency encoder. Additionally, multi-modal prediction is an efficient way to address future uncertainty. Existing auto-encoder modules are extended with static scene information and future ground truth for multi-modal trajectory prediction. Experimental results on complex scenes demonstrate the superior performance of our method in comparison to existing approaches.
Occlusions handling poses a significant challenge to many computer vision and pattern recognition applications. Recently, Synthetic Aperture Imaging (SAI), which uses more than two cameras, is widely applied to reconstruct occluded objects in complex scenes. However, it usually fails in cases of heavy occlusions, in particular, when the occluded information is not captured by any of the camera views. Hence, it is a challenging task to generate a realistic all-in-focus synthetic aperture image which shows a completely occluded object. In this paper, semantic inpainting using a Generative Adversarial Network (GAN) is proposed to address the above-mentioned problem. The proposed method first computes a synthetic aperture image of the occluded objects using a labeling method, and an alpha matte of the partially occluded objects. Then, it uses energy minimization to reconstruct the background by focusing on the background depth of each camera. Finally, the occluded regions of the synthesized image are semantically inpainted using a GAN and the results are composited with the reconstructed background to generate a realistic all-in-focus image.

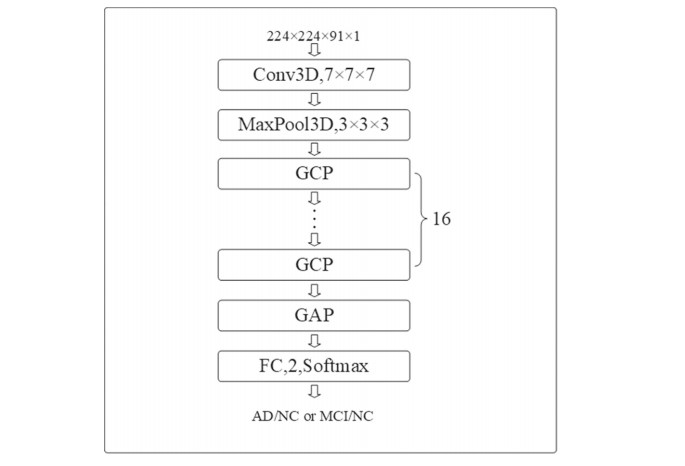
Being able to collect rich morphological information of brain, structural magnetic resonance imaging (MRI) is popularly applied to computer-aided diagnosis of Alzheimer’s disease (AD). Conventional methods for AD diagnosis are labor-intensive and typically depend on a substantial amount of hand-crafted features. In this paper, we propose a novel framework of convolutional neural network that aims at identifying AD or normal control, and mild cognitive impairment or normal control. The centerpiece of our method are pseudo-3D block and expanded global context block which are integrated into residual block of backbone in a cascaded manner.
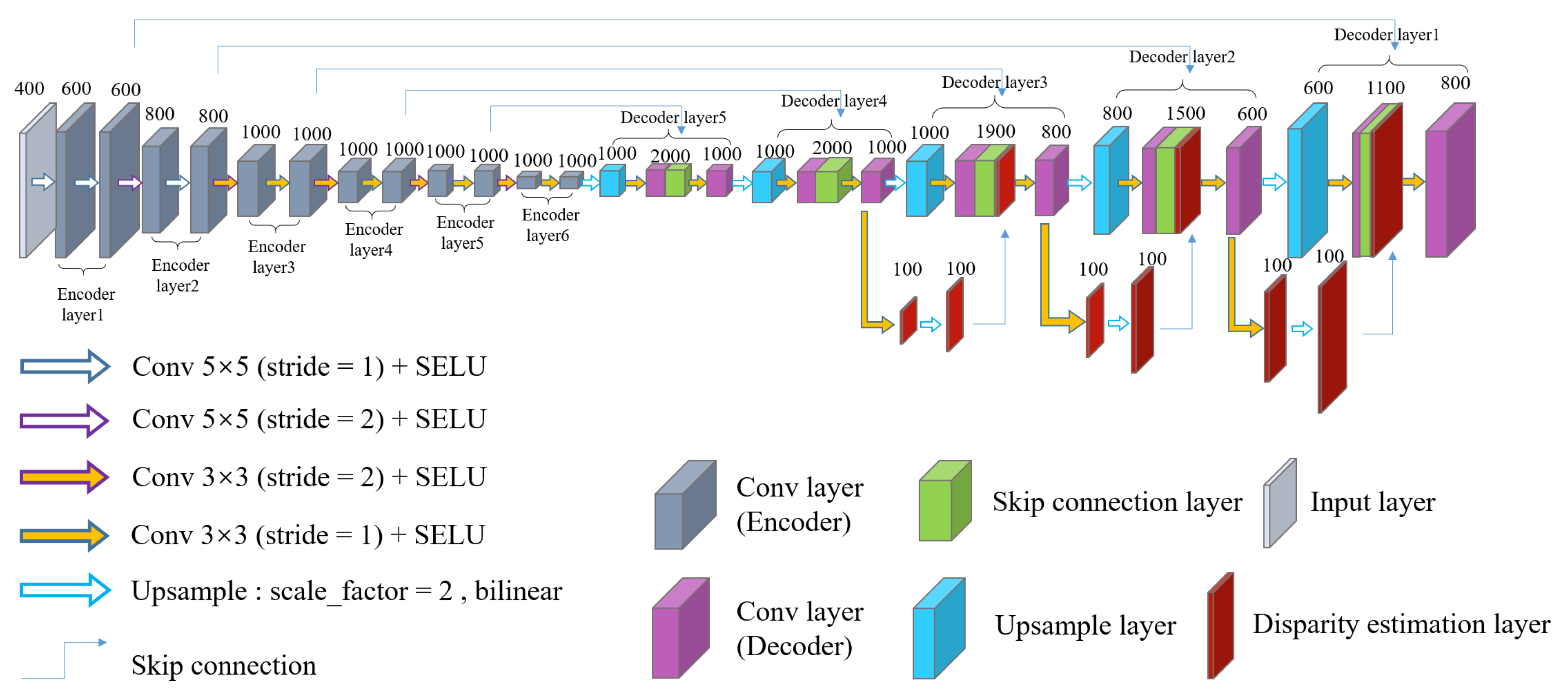
In recent years, disparity estimation of a scene based on deep learning methods has been extensively studied and significant progress has been made. Motivated by the results of traditional methods that multi-view methods are more accurate than monocular methods,especially for scenes that are textureless and have thin structures, in this paper, we present MDEAN, a new deep convolutional neural network to estimate disparity using multi-view images with an asymmetric encoder–decoder network structure.
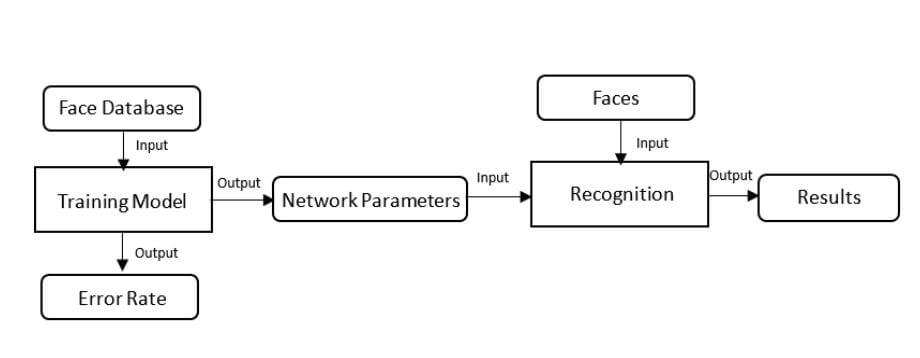
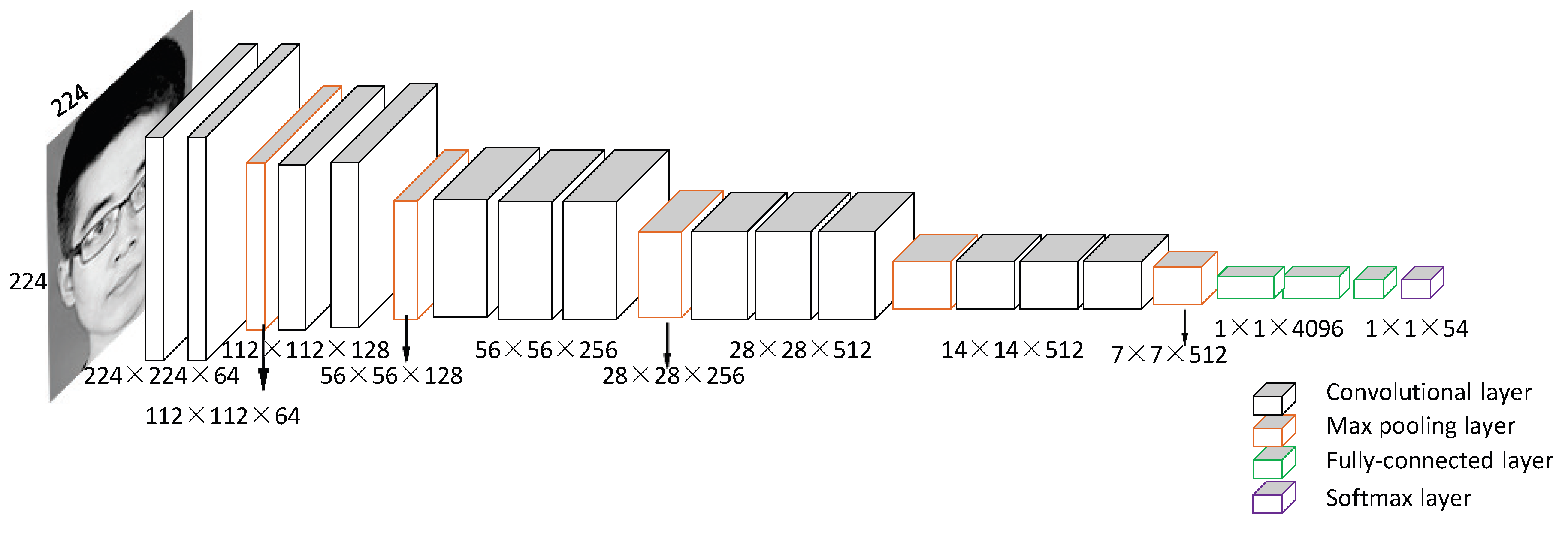
Recently, many face recognition algorithms via deep learning have achieved promising results with large-scale labeled samples. However, due to the difficulties of collecting samples, face recognition using convolutional neural networks (CNNs) for daily attendance taking remains a challenging problem. In this project, we address this problem using data augmentation through geometric transformation, image brightness changes, and the application of different filter operations. In addition, we determine the best data augmentation method based on orthogonal experiments.
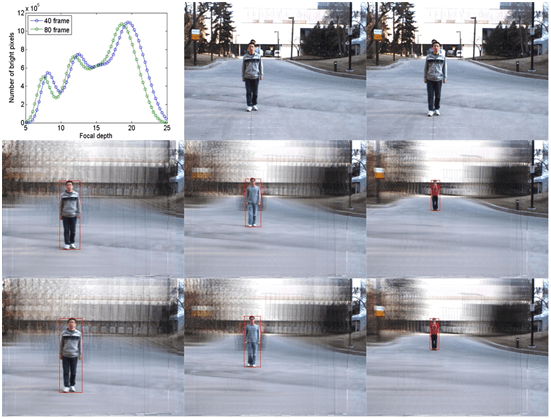
Object tracking in crowded spaces is a challenging but very important task in computer vision applications. However, due to interactions among large-scale pedestrians and common social rules, predicting the complex human mobility in a crowded scene becomes difficult. We propose a novel human trajectory prediction model in a crowded scene called the social-affinity LSTM model. Our model can learn general human mobility patterns and predict individual’ s trajectories based on their past positions, in particular, with the influence of their neighbors in the Social Affinity Map (SAM).

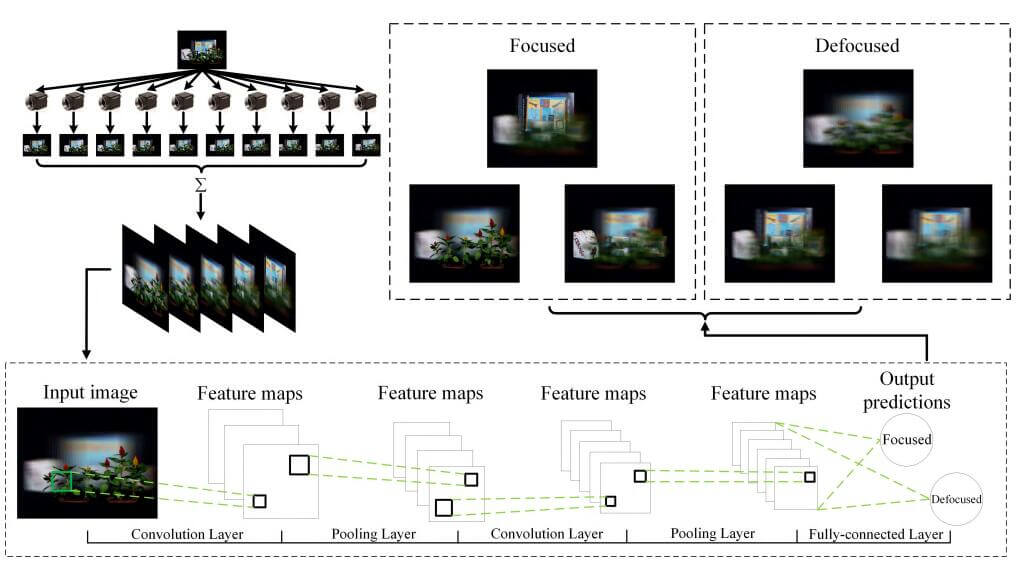
Synthetic aperture imaging is a technique that mimics a camera with a large virtual convex lens with a camera array. Objects on the focal plane will be sharp and off the focal plane blurry in the synthesized image, which is the most important effect that can be achieved with synthetic aperture imaging. Unlike conventional focus estimation methods which pick the focal plane with the minimum variance computed by the variance of corresponding pixels captured by different views in a camera array, our method automatically determines if the synthetic aperture image is focused or not from one single image of a scene without other views using a deep neural network. In particular, our method can be applied to automatically select the focal plane for synthetic aperture images.
Removing the blurriness caused by defocusing in synthetic aperture images to achieve an all-in-focus “seeing through” image is a challenging research problem. In this project, we propose a novel method to improve the image quality of synthetic aperture imaging using image matting via energy minimization by estimating the foreground and the background. We show that both the occluded objects and the background can be combined using our method to create a sharp synthetic aperture image

Object reconstruction is a technique which aims to recover the shape and appearance information of objects. Although great progress in object reconstruction has been made over the past few years, object reconstruction in occlusion situations remains a challenging problem. We propose a novel method to reconstruct occluded objects based on synthetic aperture imaging, our method uses the characteristics of synthetic aperture imaging that can effectively reduce the influence of occlusion to reconstruct the scene with occlusion.

In this project, we develop two different camera array systems. One of the camera array consists of 10 consumer grade Axis 211W Ethernet network cameras. Each Axis 211W camera captures images at a resolution of 640*480, which are stored by a central computer. The distance between two adjacent cameras is approximately 32cm. Since there are 10 cameras in the array, thus, the whole camera array simulates a virtual aperture with a size of approximately 3.0 m. The other camera array consists of 12 Point Grey Research Flea2 color cameras with a resolution of 1024*768. Each pair of cameras is connected to a single computer. The distance between two adjacent cameras is approximately 23 cm and the array simulates a camera with a virtual aperture of approximately 2.5 m.

In this project, we have developed a novel multi-object detection method using multiple cameras. Unlike conventional multi-camera object detection methods, our method detects multiple objects using a linear camera array. The array can stream different views of the environment and can be easily reconfigured for a scene compared with the overhead surround configuration. Using the proposed method, the synthesized results can provide not only views of significantly occluded objects but also the ability of focusing on the target while blurring objects that are not of interest. Our method does not need to reconstruct the 3D structure of the scene, can accommodate dynamic background, is able to detect objects at any depth by using a new synthetic aperture imaging method based on a simple shift transformation, and can see through occluders.
In this project, we propose a novel multi-object detection method using multiple camera arrays. Our detection algorithm calibrates two camera arrays based on a simple shift transformation. And also, the object can be shown in two different sides of the view from each camera array. Compare with one camera array synthetic aperture detection, our method can handle the small depth difference between the objects. What is more, instead of focusing on parallel plane, our method can focus on tilted plane. The experimental results show that the proposed method has a good performance and can successfully detect the objects within a small depth range.

In this project, according to the designed experiment, we systematically evaluated the quality of synthetic aperture image by several widely used image quality metrics. And, determine the performance of these metrics on synthetic aperture image. Then, using some good performance metrics on autofocusing to determine on which focal plane is hidden object.

Conventionally, students attendance records are taken manually by teachers through roll calling in the class. It is time-consuming and prone to errors. Moreover, records of attendance are difficult to handle and preserve for the longterm. We propose a more conveniently method of attendance statistics, which achieved through the Convolutional Neural Network (CNN).